11月1日🧎🏻♀️,14:00至15:30間🪷,電氣恒达舉辦了一場以“深度強化學習的新趨勢👨🏻🎤:不同的基於深度策略的梯度”為主題的網絡講座。由享譽國際的Hamido Fujita教授主講,講座聚焦於深度強化學習領域的最新進展,特別關註了一種創新的深度強化學習方法——Different Deep Policy based Gradients(DDPG),該方法基於不同深度策略的理念。
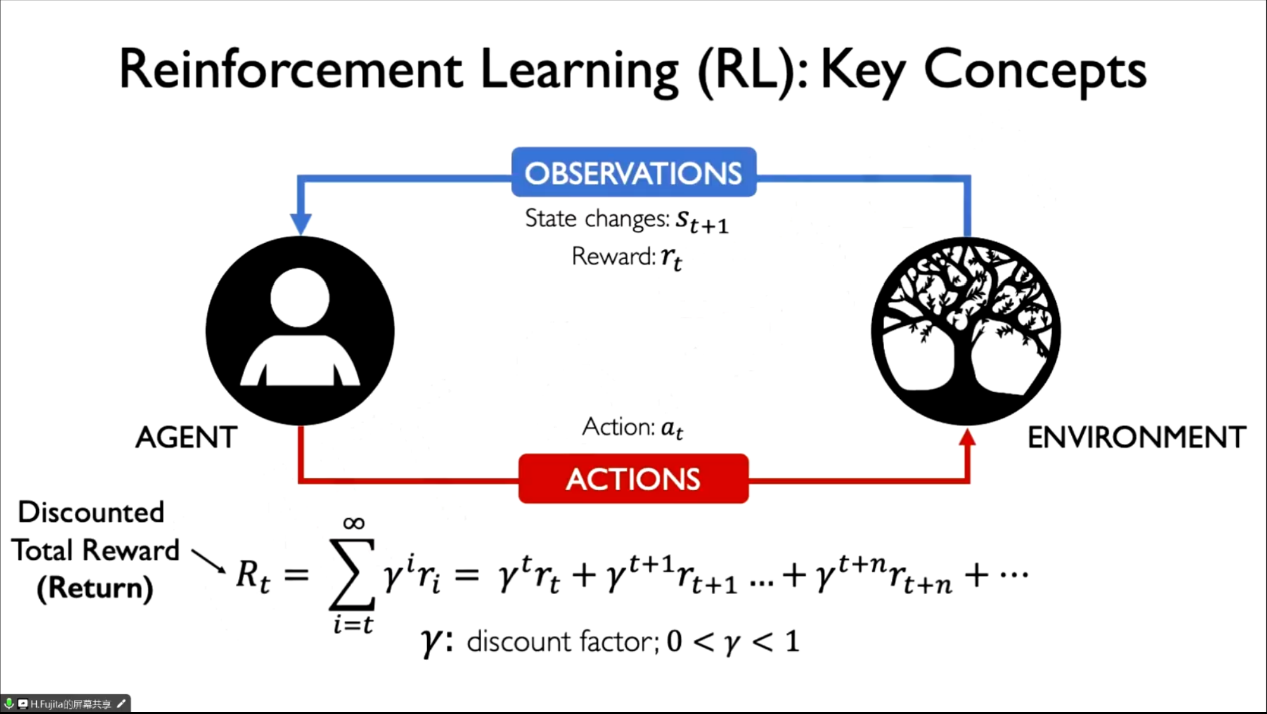
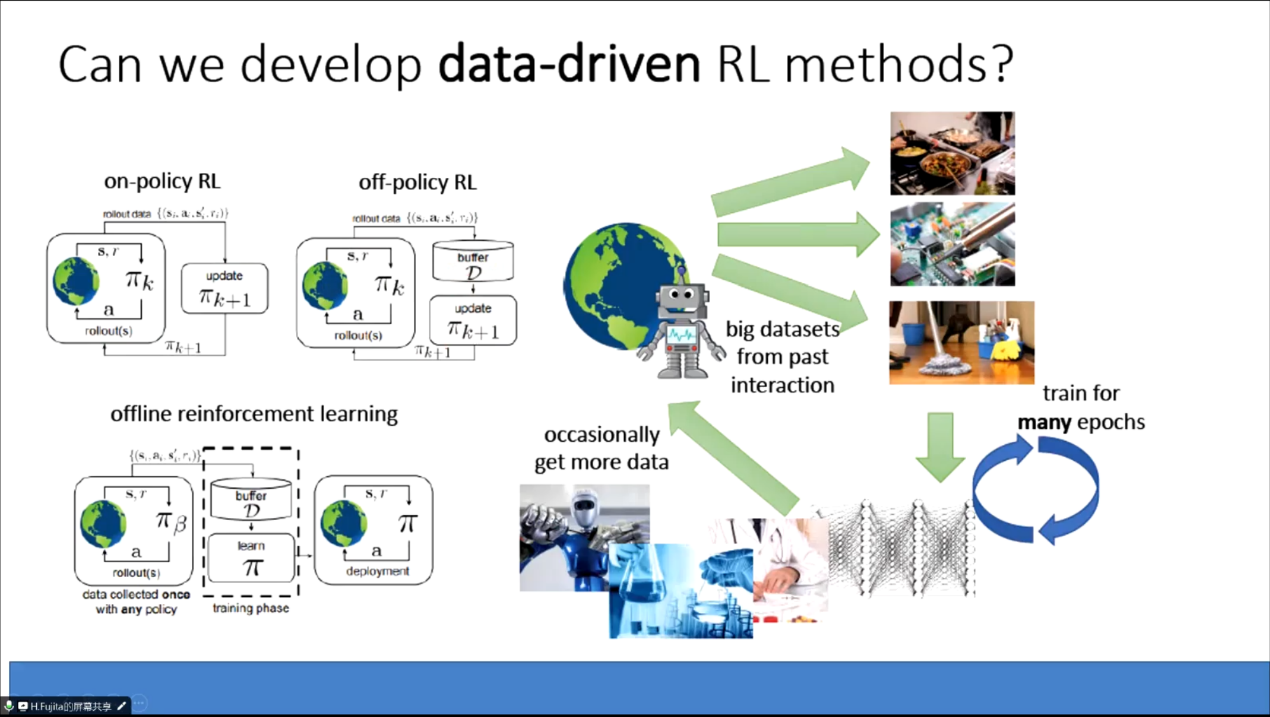
近年來,深度強化學習在人工智能領域取得了顯著的進展→🧎🏻➡️。在這次講座中,Hamido Fujita教授介紹了DDPG方法,並強調了其在復雜環境中實現智能體高效學習的重要性。DDPG方法融合了深度神經網絡在函數逼近方面的優勢和策略梯度方法在優化策略方面的優勢,為智能體在復雜環境中實現高效學習提供了嶄新的思路。

Fujita教授在講座中指出,DDPG方法的獨特之處在於其基於不同深度策略🧑🏿🦳,結合了深度神經網絡和策略梯度方法的優勢。這種綜合性的方法使得智能體能夠更好地適應多變的環境,提高學習效率,並為解決復雜問題提供了更為靈活的解決方案。
Hamido Fujita教授的講座深入淺出,引導聽眾深入了解DDPG方法的核心理念和應用前景🦷。他在演講中闡述了該方法在實際問題中的成功案例💥,並強調了深度強化學習在推動人工智能領域不斷發展中的關鍵作用。
與會師生通過騰訊會議鏈接👰🏿,全程參與了講座,關於Hamido Fujita教授的深度見解和對DDPG方法的解釋,更為收獲滿滿。此次講座為學術交流搭建了一個平臺,促使了對深度強化學習新趨勢的更深層次理解,不僅豐富了聽眾的學術知識,也為人工智能領域的研究者提供了一個共享思想和經驗的機會。
